# Computer Vision
The AutoTransformers library can not only be used to extract information from text or documents it can also be used to detect objects in images. In this example, we will how this can be implemented with AutoTransformers and how you can monitor the training process. The overall procedure is described below:
1. Create the dataset
2. Implement a custom dataset loader
3. Train the model using the AutoTransformers library
4. Babysit the training with ClearML
5. Predict new samples using the trained AutoTransformer
## Dataset
First of all, we want to mention that we create an artificial dataset for this example. In practice, it is possible to detect cars, cats or dogs in images. But in this example, the goal is simply to detect a bounding box and the correct label for rectangles and ellipses. The image and the corresponding bounding boxes are shown below:
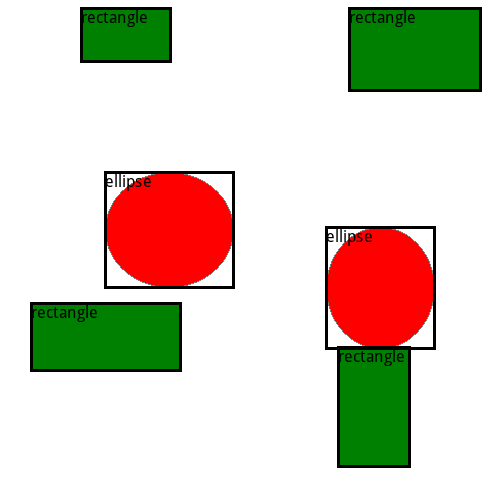 The source code to generate those samples is given below
```{eval-rst}
.. literalinclude:: computer_vision.py
:pyobject: load_sample
```
```{note}
Bounding boxes must be given in the format `[x1, y1, x2, y2]` where x1, y1 represents the upper left point and x2, y2 the lower right point. All values must be provided in pixels.
```
## Datasetloader
We have now seen how we can encode a single sample. Next, we want to implement a custom dataset loader in order to load all the training and test samples. For more information on DatasetLoader we refer to this {doc}`page `.
```{eval-rst}
.. literalinclude:: computer_vision.py
:pyobject: ImageDatasetLoader
```
## Training
Next, we can use the `ImageDatasetLoader` and the AutoTransformers library to train a model. To improve the performance its best-practice to randomly transform images. Internally, we use the [albumentations](https://albumentations.ai/) library to augment images and support all transformations that exist in this framework are also supported by AutoTransformers. Augmentations can be added as shown below:
```{eval-rst}
.. literalinclude:: computer_vision.py
:pyobject: get_config
```
In this case, we randomly flip all inputs and apply random perspective transformations. Finally, we resize all images to 320x320 px by resizing and (in case it is not square already) adding black borders. Some valid sizes are 320x320, 416x416 or 608x608 (default). Note that smaller images are faster to train, but fewer details are shown to the model which could reduce the performance. More details and transformations are available in the [albumentations documentation](https://albumentations.ai/docs/).
After adding transformations it is important to ensure that augmentations are also valid (e.g. if random brightness is selected too strongly, the image could become unrecognizable). Therefore, it is important to monitor the training process as well as some training images as seen by the model. Everything is already implemented in the AutoTransformers library. We simply need to enable the `tracking.ClearML` module when we instantiate the `AutoTransformer`` class. The following code snipped finally shows how we can train the model with custom data augmentation and enabled ClearML monitoring:
```{eval-rst}
.. literalinclude:: computer_vision.py
:pyobject: train
```
```{note}
To be able to use the `tracking.ClearML` module, you need to have a ClearML account. If you don't have one, you can create one for free [here](https://app.community.clear.ml/signup). Please also install ClearML on your machine by running `pip install clearml`.
```
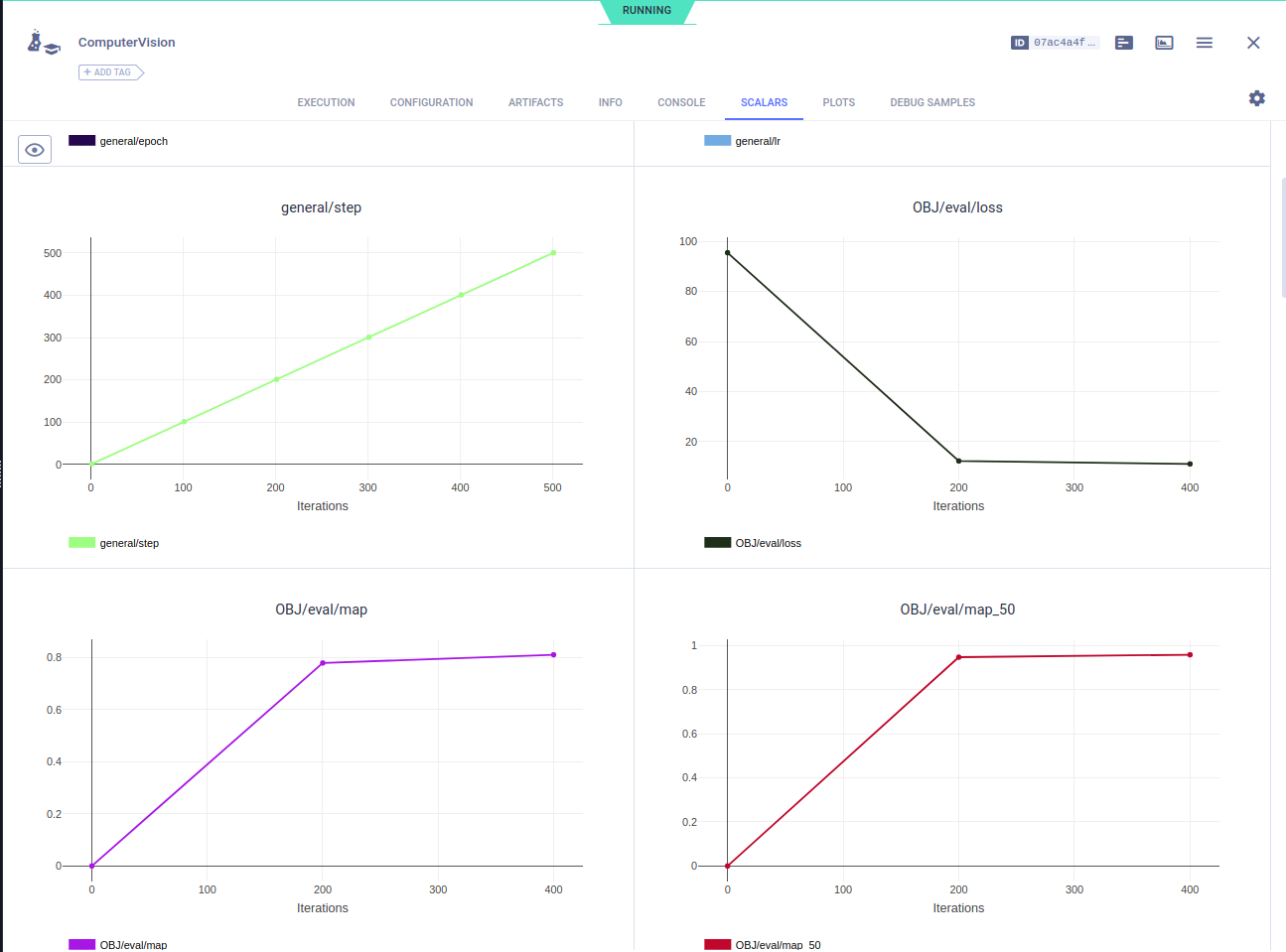
During Training, different metrics (e.g. mAP, mAR etc.) are visualized in ClearML as shown below:
The source code to generate those samples is given below
```{eval-rst}
.. literalinclude:: computer_vision.py
:pyobject: load_sample
```
```{note}
Bounding boxes must be given in the format `[x1, y1, x2, y2]` where x1, y1 represents the upper left point and x2, y2 the lower right point. All values must be provided in pixels.
```
## Datasetloader
We have now seen how we can encode a single sample. Next, we want to implement a custom dataset loader in order to load all the training and test samples. For more information on DatasetLoader we refer to this {doc}`page `.
```{eval-rst}
.. literalinclude:: computer_vision.py
:pyobject: ImageDatasetLoader
```
## Training
Next, we can use the `ImageDatasetLoader` and the AutoTransformers library to train a model. To improve the performance its best-practice to randomly transform images. Internally, we use the [albumentations](https://albumentations.ai/) library to augment images and support all transformations that exist in this framework are also supported by AutoTransformers. Augmentations can be added as shown below:
```{eval-rst}
.. literalinclude:: computer_vision.py
:pyobject: get_config
```
In this case, we randomly flip all inputs and apply random perspective transformations. Finally, we resize all images to 320x320 px by resizing and (in case it is not square already) adding black borders. Some valid sizes are 320x320, 416x416 or 608x608 (default). Note that smaller images are faster to train, but fewer details are shown to the model which could reduce the performance. More details and transformations are available in the [albumentations documentation](https://albumentations.ai/docs/).
After adding transformations it is important to ensure that augmentations are also valid (e.g. if random brightness is selected too strongly, the image could become unrecognizable). Therefore, it is important to monitor the training process as well as some training images as seen by the model. Everything is already implemented in the AutoTransformers library. We simply need to enable the `tracking.ClearML` module when we instantiate the `AutoTransformer`` class. The following code snipped finally shows how we can train the model with custom data augmentation and enabled ClearML monitoring:
```{eval-rst}
.. literalinclude:: computer_vision.py
:pyobject: train
```
```{note}
To be able to use the `tracking.ClearML` module, you need to have a ClearML account. If you don't have one, you can create one for free [here](https://app.community.clear.ml/signup). Please also install ClearML on your machine by running `pip install clearml`.
```
During Training, different metrics (e.g. mAP, mAR etc.) are visualized in ClearML as shown below:
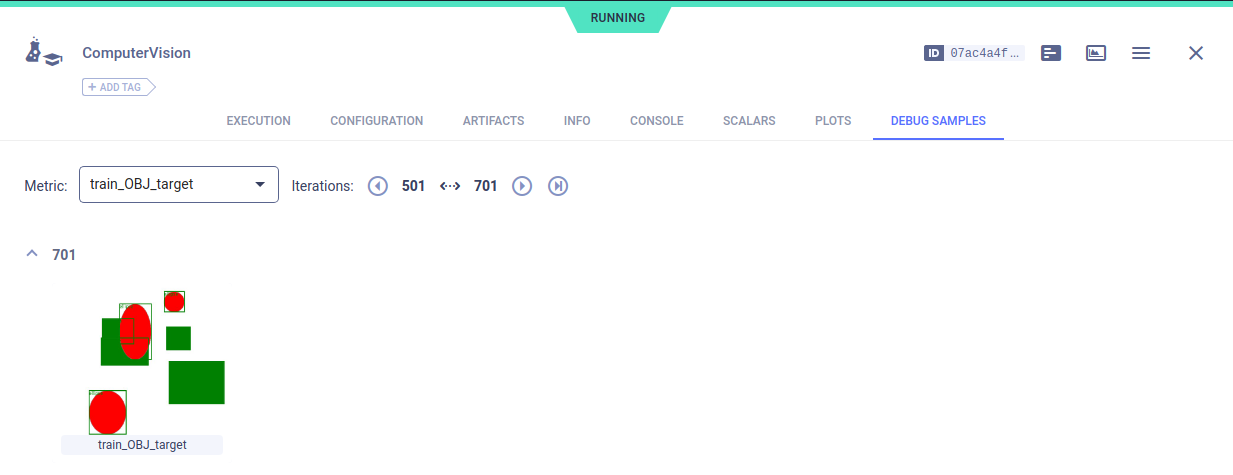
 Additionally, it is possible to visualize the training images as seen by the model. Simply open the "DEBUG SAMPLES" section in ClearML and you will see the following images:
Additionally, it is possible to visualize the training images as seen by the model. Simply open the "DEBUG SAMPLES" section in ClearML and you will see the following images:
 ## Prediction
Finally, we can use the trained model to predict new samples. The following code snippet shows how we can load a trained model and predict new samples:
```{eval-rst}
.. literalinclude:: computer_vision.py
:pyobject: predict
```
## Full source code
```{eval-rst}
.. collapse:: Source Code
:open:
.. literalinclude:: computer_vision.py
```
## Prediction
Finally, we can use the trained model to predict new samples. The following code snippet shows how we can load a trained model and predict new samples:
```{eval-rst}
.. literalinclude:: computer_vision.py
:pyobject: predict
```
## Full source code
```{eval-rst}
.. collapse:: Source Code
:open:
.. literalinclude:: computer_vision.py
```