Dataset and DatasetLoader¶
In general, you first create a dataset containing the samples together with their labels that can be used to train an AutoTransformer model. Then you use a DatasetLoader to feed this data into an AutoTransformer during training. The general idea of this concept is shown below:
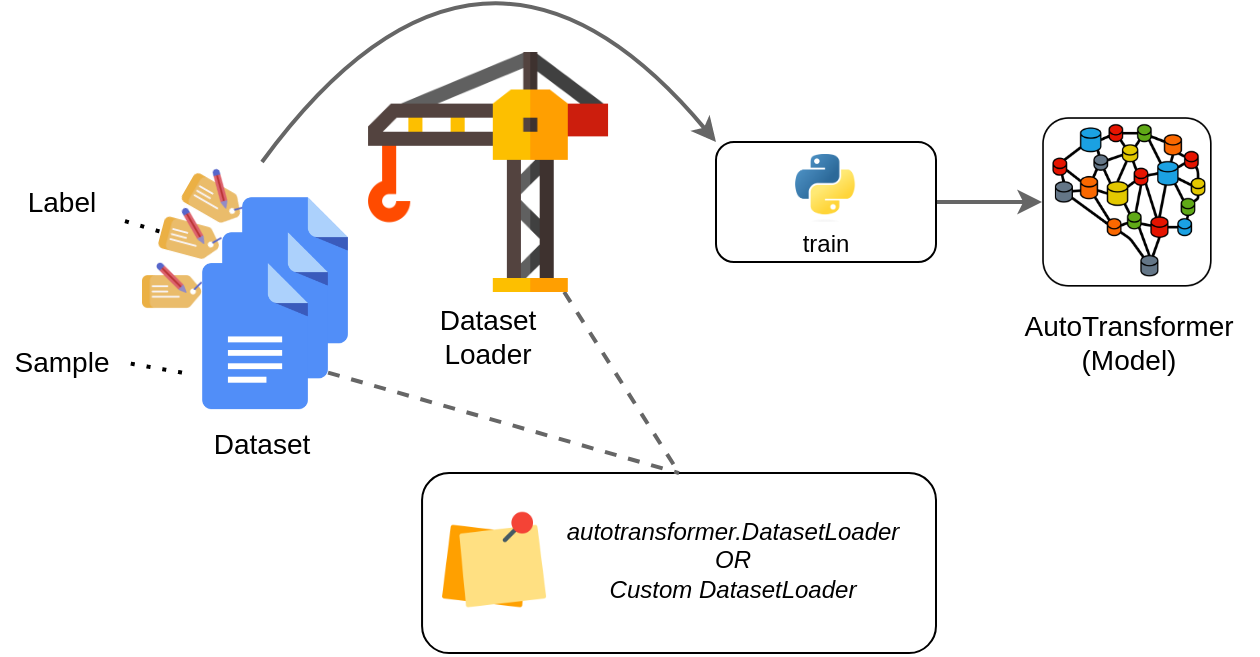
Therefore, you can use two different options to load data:
Use the DeepOpinion dataset format (as generated by the AutoTransformers wizard) and use the
autotransformers.DatasetLoaderto load your dataset.Keep your custom dataset format and implement your own, custom DatasetLoader.
In the following subsections, we describe both different methods in more detail.
autotransformers.DatasetLoader¶
In order to create the correct dataset format, we suggest to use the AutoTransformers wizard. Simply call at wizard in a command line and follow the guided project setup. AutoTransformers will then generate the correct dataset.json file for you. Check out also this tutorial.
Still, you can manually create the dataset. The following code example shows how the dataset.json file is structured. It defines a dataset with text inputs and two tasks, one TSingleClassification and one TMultiClassification.
{
"meta": {
"name": "MyDataset",
"version": "1.0.0",
"created_with": "wizard"
},
"config": [
{
"domain": "text",
"type": "IText"
},
[
{
"task_id": "YOUR_UNIQUE_TASK_ID",
"classes": ["class-0", "class-1", "class-2"],
"type": "TSingleClassification"
},
{
"task_id": "YOUR_OTHER_TASK_ID",
"classes": ["x", "y", "z"],
"type": "TMultiClassification"
}
]
],
"train": [
[
{"value": "My name is John Doe and I live in Innsbruck."},
[{"value": "class-0"},{"value": ["x","z"]}]
],
["..."]
],
"eval": ["..."],
"test": ["..."]
}
The meta object contains all additional information such as the name, a version (e.g. if you add new sampels you can increase the version) as well as how this dataset was created (e.g. wizard, manual etc.). This meta information is stored together with the trained model such that you can later reproduce how the model was created.
The config object contains that is required to train a model successfully: The input type, the tasks as well as classes. Based on this information the model can be generated with the correct number of heads. The train, eval and test contain the training samples that are used during training. Each sample is a nested list [input, [task_0, task_1, ...]] where task_0, task_1, etc. are the labels for the different tasks (e.g. single-label and multi-label classification). The config object uses the same structure to define configs for the input and tasks respectively.
When you generate the dataset.json file using the at wizard command, examples are included to show how to set inputs and tasks correctly.
Note
When your dataset only defines a single task, you can omit the nested list and instead use a plain list [input, task] to define each sample instead. The config object must also omit the list around the task config in this case.
If you represent your data in this format, you can simply use the following code to load the data:
from autotransformers import DatasetLoader
dl = DatasetLoader("path/to/dataset.json")
...
Custom DatasetLoader Implementations¶
You can also keep your current dataset format and create a custom dataset loader. In the following example, it is shown how a custom dataset loader for the IMDB dataset can be implemented. The format of the dataset is shown below:
aclImdb
|--train
| |--neg
| | |--0_3.txt
| | |--x_y.txt
| | ...
| |--pos
| | |--0_9.txt
| | |--x_y.txt
| | ...
|
|--test
| |
| ...
The train folder contains all samples that are used to train your AutoTransformer, while the test folder contains samples that are not used during training in order to evaluate the performance of your model on unseen data later on. Both folders (train, test) contain one subfolder for each class (neg, pos) that should be predicted later on.
To implement a DatasetLoader correctly and ensure that the correct data is used for training, a new ImdbDatasetLoader class is implemented with the following requirements:
config: The config property defines the dataset configuration. More precisely, it defines (1) the input type (in this caseIText) as well as all tasks that should be solved (in this case only one task, namely TSingleClassification). The following code-snipped shows how this property can be implemented inImdbDatasetLoader:@property def config(self): # Models are always defined via inputs (text, document images) + combinations of expected outputs (classification, information extraction etc.) # The config can be used to set call names and to define ids in order to access the outputs later on again. # Finally, the dataset must be of the same structure to train the device AND predictions also return the same structure as shown below. return IText.Config(), ( TSingleClassification.Config(task_id="review", classes=["pos", "neg"]), )
Note
The return value of config is a tuple of (inputs, tasks). As we support multiple tasks in parallel (e.g. InformationExtraction + Classification), the tasks output is, again, a tuple as shown above.
train_ds,test_ds,eval_ds: We must provide three datasets in order to train models correctly.train_ds: Used to train the modeleval_ds: Used internally to tune hyperparameters, stop early etc.test_ds: Needed to finally evaluate the model on unseen data TheATDatasetclass can be used to create those different datasets and to load samples dynamically. In the following code example, this is shown for the ImdbDataset and a detailed tutorial how this DatasetLoader can be used is shown here
meta(Optional): You can also provide meta information such as the version of your dataset, the name and how you created it. Simply add a propertymetato the dataset loader and create it withmeta = DatasetMeta(...)which can be imported viafrom autotransformers.dataset_loader import DatasetMeta. Example:@property def meta(self): return DatasetMeta(name="IMDB", version="1.0.0", created_with="Manual")
Full source code¶
Source Code
class ImdbDatasetLoader: # # The dataset loader must provide metadata (the model is coupled with some dataset version etc.) # a configuration (how the model is trained and what it expects as input and output) and the dataset itself. # The dataset must be provided via train_ds, test_ds and eval_ds. If the eval_ds is None, AT will automatically # split the train_ds into train and eval in order to avoid overfitting due to hyperparameter tuning. # def __init__(self, path) -> None: super().__init__() self.path = Path(path) self.train_ds = self._load("train") self.test_ds = self._load("test") self.eval_ds = None @property def meta(self): return DatasetMeta(name="IMDB", version="1.0.0", created_with="Manual") @property def config(self): # Models are always defined via inputs (text, document images) + combinations of expected outputs (classification, information extraction etc.) # The config can be used to set call names and to define ids in order to access the outputs later on again. # Finally, the dataset must be of the same structure to train the device AND predictions also return the same structure as shown below. return IText.Config(), ( TSingleClassification.Config(task_id="review", classes=["pos", "neg"]), ) def _load(self, name): if not self.path.exists(): self._download() samples_filenames = self._get_samples(name) def load_sample(idx): text_file, label = samples_filenames[idx] return (IText(text_file.read_text()), (TSingleClassification(label),)) return ATDataset(self.config, load_sample, length=len(samples_filenames)) def _download(self): print("Download IMDB dataset...") os.makedirs(self.path) tar_path = self.path / "aclImdb_v1.tar.gz" urllib.request.urlretrieve( # nosec B310 "http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz", tar_path, ) with tarfile.open(tar_path) as tar_file: tar_file.extractall(self.path) # nosec B202 os.remove(tar_path) def _get_samples(self, name): path = self.path / "aclImdb" / name samples = [(f, c) for c in ["pos", "neg"] for f in (path / c).iterdir()] shuffle(samples) return samples