Document¶
AutoTransformers can be used to train models on documents in order to extract information or classify them. In this GettingStarted we give a brief overview of the process and show how to use AutoTransformers to train a model on a document dataset.
Documents must be preprocessed before it can be used. For the training data, this is done once for all samples. During prediction this process is executed for each sample individually:
Convert the PDF to an Image
Extract the text and bounding boxes from the image using a OCR scanner
Label the text with the bounding boxes for information extraction or classify the document for classification
Train the model using AutoTransformers
Predict new samples using the trained model
The overall main procedure is shown below:
def main():
# Load document and scan with OCR
image = load_pdf_as_image("document.pdf")
bboxes = run_ocr(image)
bboxes = label_bboxes(bboxes)
# Train an AutoTransformer model
at = train(image, bboxes)
# Predict new documents with this model
predict(at)
In the following subsections, we will go into more detail about each step.
1. Convert the PDF to an Image¶
To demonstrate this process, we use only one PDF file. In a real-world scenario, you would have a folder with multiple PDF files that can be used for training or later on a new PDF that should be predicted. You can download this PDF file.
First of all, we load the pdf file into memory. We not directly load the pdf file, instead we load it as an image. This is because the OCR scanner we use later on only accepts images as input:
def load_pdf_as_image(pdf_path):
"""This function loads a given PDF file and converts it to an PIL image which can later
be used by OCR scanner.
Note that it is assumed that pdf2image is already installed. Otherwise, please install
it with `pip install pdf2image Pillow`.
"""
pages = convert_from_path(pdf_path)
return pages[0]
2. Run OCR Scanner¶
Next we run the OCR scanner to extract the text as well as all bounding boxes from the original document. The document can be a scanned document and, therefore, OCR scanning is required. We recommend using the open-source OCR Wrapper that we developed which abstracts different OCR implementations. Nevertheless, we fully support other OCR scanners as well. In this example, we use the ocr_wrapper and easy_ocr and set the ocr settings to english:
def run_ocr(image):
"""We can use the OCR wrapper to extract text from the image.
The OCR wrapper will return a list of bounding boxes with the text using an arbitrary
OCR engine. The OCR wrapper is an open-source project from DeepOpinion to improve and simplify OCR
that can be found here: https://github.com/deepopinion/ocr_wrapper
You can install the wrapper via `pip install git+https://github.com/deepopinion/ocr_wrapper`
and easyocr via `pip install easyocr`
"""
ocr = EasyOCR(languages=["en"])
return ocr.ocr(image)
3. Label the bounding boxes¶
Next we label all bounding boxes that were extracted from the OCR scanner. Therefore, we list all bounding boxes and ask the user to label the text. Here you can see our label selection:
Please label the text (enter to skip): 'AutoTransformers'
Please label the text (enter to skip): 'Example'
Please label the text (enter to skip): 'Name:'
Please label the text (enter to skip): 'Max Mustermann'
name
Please label the text (enter to skip): 'Birthday:'
Please label the text (enter to skip): '17.05.1991'
birthday
Please label the text (enter to skip): 'Country:'
Please label the text (enter to skip): 'Austria'
country
Please label the text (enter to skip): 'City:'
Please label the text (enter to skip): 'Innsbruck'
city
Please label the text (enter to skip): 'DeepOpinion'
company
Warning
Its not recommendet to label the bounding boxes manually. Instead, we recommend using the (DeepOpinion Studio)[https://studio.deepopinion.ai] that allows you to label the bounding boxes in a user-friendly way. The method shown here is only for demonstration purposes.
4. Train the AutoTransformer model¶
Next we train the AutoTransformer model. In order to train such a model we can either write a custom dataset loader or we can also format our dataset and use the generic dataset loader as we described in the data getting started tutorial. In this example, we decided to implement a generic dataset loader. This implementation is shown below:
class DemoDocumentDatasetLoader:
"""Warning: Usually, many different documents are labeled. For this demo, we only use
one document and duplicate it n times simply to demonstrate the document workflow. Please
also note that the train, test and eval sets are usually not the same.
"""
def __init__(self, doc, bboxes) -> None:
# Extract all classes from the bounding boxes
# Note: We sort classes to ensure a correct order also for prediction.
self.classes = list({[d.label for d in bboxes]})
# Create train, eval and test splits.
self.train_ds = self._create_ds(doc, bboxes, size=128)
self.test_ds = self._create_ds(doc, bboxes, size=32)
self.eval_ds = self._create_ds(doc, bboxes, size=32)
@property
def meta(self):
"""The meta data of the dataset is stored with the trained model such that we
can later reproduce the results. Whenever we change the dataset, we should also
change the version number.
"""
return DatasetMeta(name="DocumentDemo", version="1.0.0", created_with="Manual")
@property
def config(self):
return IDocument.Config(ocr="easyocr", ocr_config={"languages": ["en"]}), (
TInformationExtraction.Config(
task_id="IE",
classes=self.classes,
none_class_id=self.classes.index(None),
),
)
def _create_ds(self, doc, bboxes, *, size):
def load_sample(idx):
labels = [d.label for d in bboxes]
return (IDocument(doc, bboxes), (TInformationExtraction(labels),))
return ATDataset(self.config, load_sample, length=size)
We can now use this DemoDocumentDatasetLoader to train an AutoTransformer model:
def train(doc, bboxes):
dl = DemoDocumentDatasetLoader(doc, bboxes)
at = AutoTransformer(
[
("engine/stop_condition/type", "MaxEpochs"),
("engine/stop_condition/value", 3),
]
)
at.init(dataset_loader=dl, path=".models/document/demo")
at.train(dl)
return at
For more information on how to use AutoTransformers to train new models please refer to the AutoTransformer getting started tutorial.
5. Predict new data¶
Finally, we can use this trained model to predict new data. We simply specify the path to the pdf document and the trained AutoTransformer model will do the rest:
def predict(at):
"""Write labels directly into the image and save it locally."""
doc, labels = at("document.pdf")
colors = {
"name": "blue",
"city": "green",
"birthday": "orange",
"country": "magenta",
"company": "cyan",
}
label_colors = ["black" if p is None else colors[p] for p in labels.value]
img = draw_bboxes(
img=doc.image,
bboxes=doc.bboxes,
texts=labels.value,
colors=label_colors,
fontsize=26,
)
img.save("doc_ocr.png")
Note
In case an OCR scanner that is not supported by the ocr_wrapper is used, the predict method can be overwritten to use the OCR scanner of choice by manually providing a IDocument rather than a str as input.
The IDocument then contains all bounding boxes that were created by the custom OCR scanner.
For demonstration purposes, we plot the results into the original document and show the results below. Each bounding boxes is drawn in black if it has no label, otherwise its shown in red together with the label text:
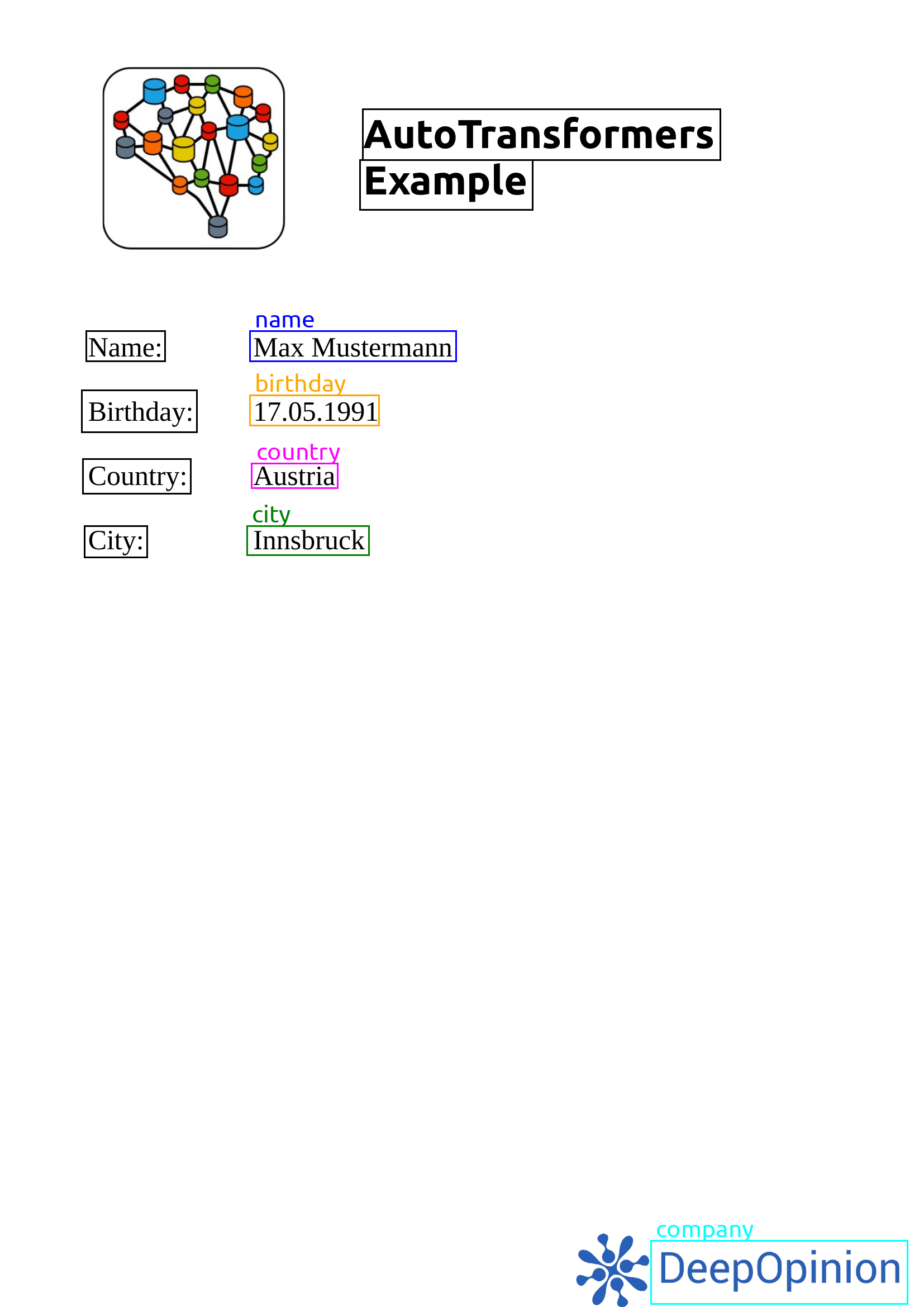
Full source code¶
Source Code
""" An example pipeline for training a document AutoTransformer model. """ from ocr_wrapper import EasyOCR from autotransformers import AutoTransformer, init_logging, ATDataset from autotransformers.dataset_loader import DatasetMeta from autotransformers.types import IDocument from autotransformers.domains.document.types import TInformationExtraction from autotransformers.utils.bbox_utils import draw_bboxes from pdf2image import convert_from_path class DemoDocumentDatasetLoader: """Warning: Usually, many different documents are labeled. For this demo, we only use one document and duplicate it n times simply to demonstrate the document workflow. Please also note that the train, test and eval sets are usually not the same. """ def __init__(self, doc, bboxes) -> None: # Extract all classes from the bounding boxes # Note: We sort classes to ensure a correct order also for prediction. self.classes = list({[d.label for d in bboxes]}) # Create train, eval and test splits. self.train_ds = self._create_ds(doc, bboxes, size=128) self.test_ds = self._create_ds(doc, bboxes, size=32) self.eval_ds = self._create_ds(doc, bboxes, size=32) @property def meta(self): """The meta data of the dataset is stored with the trained model such that we can later reproduce the results. Whenever we change the dataset, we should also change the version number. """ return DatasetMeta(name="DocumentDemo", version="1.0.0", created_with="Manual") @property def config(self): return IDocument.Config(ocr="easyocr", ocr_config={"languages": ["en"]}), ( TInformationExtraction.Config( task_id="IE", classes=self.classes, none_class_id=self.classes.index(None), ), ) def _create_ds(self, doc, bboxes, *, size): def load_sample(idx): labels = [d.label for d in bboxes] return (IDocument(doc, bboxes), (TInformationExtraction(labels),)) return ATDataset(self.config, load_sample, length=size) def load_pdf_as_image(pdf_path): """This function loads a given PDF file and converts it to an PIL image which can later be used by OCR scanner. Note that it is assumed that pdf2image is already installed. Otherwise, please install it with `pip install pdf2image Pillow`. """ pages = convert_from_path(pdf_path) return pages[0] def run_ocr(image): """We can use the OCR wrapper to extract text from the image. The OCR wrapper will return a list of bounding boxes with the text using an arbitrary OCR engine. The OCR wrapper is an open-source project from DeepOpinion to improve and simplify OCR that can be found here: https://github.com/deepopinion/ocr_wrapper You can install the wrapper via `pip install git+https://github.com/deepopinion/ocr_wrapper` and easyocr via `pip install easyocr` """ ocr = EasyOCR(languages=["en"]) return ocr.ocr(image) def label_bboxes(doc_ocr): """This function shows each bounding box that was extracted from a single document with ocr and asks the user to enter a label for each bounding box. Note: We suggest using a UI tool for labeling, that can later be used to extend your dataset or to change wrong labels. We provide this functionality already in our Studio (https://studio.deepopinion.ai) """ for bbox in doc_ocr: print(f"Please label the text (enter to skip): '{bbox.text}'") bbox.label = input() or None return doc_ocr def train(doc, bboxes): dl = DemoDocumentDatasetLoader(doc, bboxes) at = AutoTransformer( [ ("engine/stop_condition/type", "MaxEpochs"), ("engine/stop_condition/value", 3), ] ) at.init(dataset_loader=dl, path=".models/document/demo") at.train(dl) return at def predict(at): """Write labels directly into the image and save it locally.""" doc, labels = at("document.pdf") colors = { "name": "blue", "city": "green", "birthday": "orange", "country": "magenta", "company": "cyan", } label_colors = ["black" if p is None else colors[p] for p in labels.value] img = draw_bboxes( img=doc.image, bboxes=doc.bboxes, texts=labels.value, colors=label_colors, fontsize=26, ) img.save("doc_ocr.png") def main(): # Load document and scan with OCR image = load_pdf_as_image("document.pdf") bboxes = run_ocr(image) bboxes = label_bboxes(bboxes) # Train an AutoTransformer model at = train(image, bboxes) # Predict new documents with this model predict(at) if __name__ == "__main__": init_logging() main()