Getting Started - Manual¶
Note
Please note that we suggest to use the AutoTransformers wizard to get started. This wizard will help you to create your dataset, and it will automatically generate the train.py as well as predict.py script.
In the previous tutorial, you have seen how you can use the AutoTransformers wizard to generate a complete project, without the need for coding a single line. In this example, it is shown how you can train an AutoTransformer on documents without using the AutoTransformers wizard. More precisely, we will train a “MovieAT” model that will predict, whether a movie review was positive or negative. In this specific case, the input format is text and the model should solve the task to classify whether the input was positive (pos) or negative (neg): An overview of the system that we develop next is shown below:
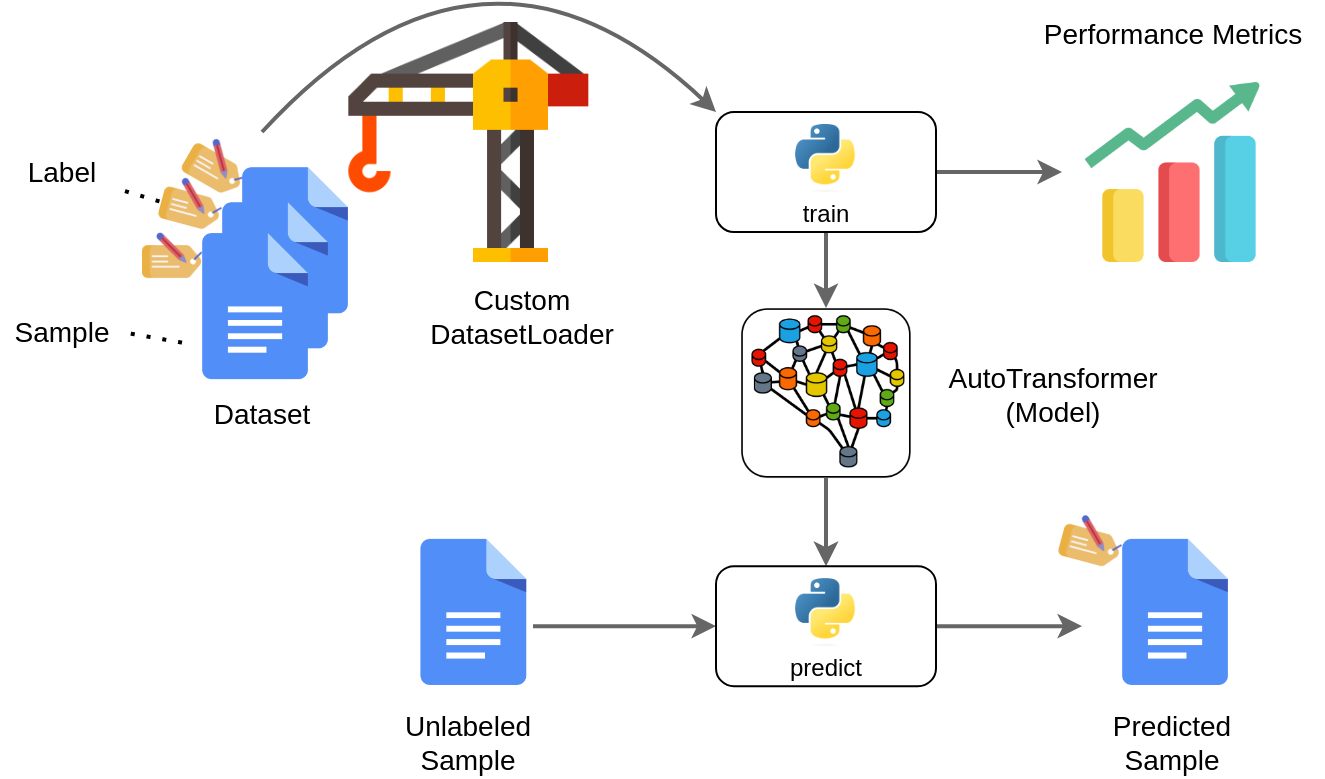
In the following subsections, you will learn how each component can be implemented from scratch using the AutoTransformers library.
Step 1: Define and think about typing¶
Its very important to understand that AutoTransformers is a library to transform your data into ML models. Therefore, you need to define what input data you have and what output you expect. AutoTransformers implements different input types (e.g. text, documents, images) and different output types that can be used simultaneously (classification, information extraction etc.).
So first we need to define the input and output types that we expect. In this example we want to classify
text input into a positive or negative sentiment. In AutoTransformers Types are always named
with leading I... and for output types T... is used. So we want a model with (IText, ISingleClassification).
There is no need to explicitly define this in the AT model class, instead its enough to train the model with the correct dataset and the model will automatically learn the correct input and output types. Therefore, its very important that we define the dataset correctly. This is shown in the next step.
Note
To find all types you can use the console and type at man --domain=text in order to print all supported types
for the text domain. Clearly, the same can be done for all domains (text, document, computer vision).
Step 2: Implement Dataset and DatasetLoader¶
The DatasetLoader defines your data and, therefore, which types a trained AT model expects in future and it also
defines which data is returned by an AT model. The config property of the DatasetLoader defines the input as
well as outputs. Outputs such as ISingleClassification need additional configuration in our example we need
to define which classes (pos, neg) exist. Additionally the meta section defines more information that is quite
useful later on when we want to check on which data a model was trained. Finally, the DatasetLoader provides
the train_ds, test_ds and eval_ds properties that return the data in the correct format used for training and
evaluation.
class ImdbDatasetLoader:
#
# The dataset loader must provide metadata (the model is coupled with some dataset version etc.)
# a configuration (how the model is trained and what it expects as input and output) and the dataset itself.
# The dataset must be provided via train_ds, test_ds and eval_ds. If the eval_ds is None, AT will automatically
# split the train_ds into train and eval in order to avoid overfitting due to hyperparameter tuning.
#
def __init__(self, path) -> None:
super().__init__()
self.path = Path(path)
self.train_ds = self._load("train")
self.test_ds = self._load("test")
self.eval_ds = None
@property
def meta(self):
return DatasetMeta(name="IMDB", version="1.0.0", created_with="Manual")
@property
def config(self):
# Models are always defined via inputs (text, document images) + combinations of expected outputs (classification, information extraction etc.)
# The config can be used to set call names and to define ids in order to access the outputs later on again.
# Finally, the dataset must be of the same structure to train the device AND predictions also return the same structure as shown below.
return IText.Config(), (
TSingleClassification.Config(task_id="review", classes=["pos", "neg"]),
)
def _load(self, name):
if not self.path.exists():
self._download()
samples_filenames = self._get_samples(name)
def load_sample(idx):
text_file, label = samples_filenames[idx]
return (IText(text_file.read_text()), (TSingleClassification(label),))
return ATDataset(self.config, load_sample, length=len(samples_filenames))
def _download(self):
print("Download IMDB dataset...")
os.makedirs(self.path)
tar_path = self.path / "aclImdb_v1.tar.gz"
urllib.request.urlretrieve( # nosec B310
"http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz",
tar_path,
)
with tarfile.open(tar_path) as tar_file:
tar_file.extractall(self.path) # nosec B202
os.remove(tar_path)
def _get_samples(self, name):
path = self.path / "aclImdb" / name
samples = [(f, c) for c in ["pos", "neg"] for f in (path / c).iterdir()]
shuffle(samples)
return samples
Its not necessary to create your own DatasetLoader each time. Instead its also possible to use a custom json format as shown in this tutorial.
Step 3: Train¶
Next, we can use our custom ImdbDatasetLoader to train and create a MovieAT model. The model will be stored at .models/MovieAT from where we can load it later on.
def train(path_dataset, path_model, sys_config=None):
dl = ImdbDatasetLoader(path=path_dataset)
at = AutoTransformer(sys_config).init(dataset_loader=dl, path=path_model)
test_metrics = at.train(dl)
print(test_metrics)
# Prints all metrics that are available for this model and domain.
# For example:
# Metric Value
# ----------------------- --------
# review/test/accuracy 0.9468
# review/test/weighted_f1 0.946799
# review/test/loss 0.150823
# The "review" is set as we defined the task_id in the config above.
# This way we can retrieve scores for each task individually.
at.finish()
del at
return test_metrics
Note that we usually train the model only once, but predict often afterwards.
Step 4: Predict¶
Finally, we can implement the predict.py script that loads our MovieAT model and predicts new data based on patterns that the model learned during training:
def predict(path_model):
at = AutoTransformer().load(path=path_model)
#
# Predict with IText as we defined this input in our specification above.
#
print("# Single sample prediction")
input = IText("I really really love this movie")
result = at(input)
# As we defined the AT model to be a (IText, TSingleClassification), we know that the output of AT is the same, so -> (IText, TSingleClassification)
# AutoTransformers returns a NamedTuple with input, output (can also be accessed via result.input, result.output and result[0], result[1]).
# As we are the users of AT we can also set type hints in order to work with it later on. AT can't set specific type hints as predictions are dependent
# on how the user trained AT, but the user must know this otherwise he/she can't train it.
input: IText = result.input # == result[0]
prediction: TSingleClassification = result.output # == result[1]
print(type(input)) # Prints: <class 'autotransformers.types.IText'>
print(
type(prediction)
) # Prints: <class 'autotransformers.domains.text.types.TSingleClassification'>
print("Value:", prediction.value) # Prints: Value: pos
print("Confidence", prediction.confidence) # Prints: Confidence 0.9379566311836243
# Implicilty, we can also use a string that is internally converted to IText, sometimes nicer to read.
print("\n# Sample prediction of string input")
input = IText("I really really love this movie")
output = at(input)
print(output[1].value) # Prints: pos
# We also allow batching of inputs in order to speed up predictions as we exploit the parallelism of GPUs better.
# Then, the output is also a list with predictions for each sample.
print("\n# Batched predictions and batched outputs")
output = at(
["I really really love this movie", "I hate this movie, it was super boring"]
)
assert all(isinstance(output[i].input, IText) for i in range(len(output)))
assert all(
isinstance(output[i].output, TSingleClassification) for i in range(len(output))
)
print(output[0].output.value) # Prints: pos
print(output[1].output.value) # Prints: neg
# Finally, we can clean up memory of the model.
# Still we also need to delete the AutoTransformer object as it holds the model in memory on CPU + GPU.
at.finish()
del at
Please note that the input format must match with your dataset definition. The output that is returned then also depends on the same definition i.e. it depends on how your model was trained. This allows AutoTransformers to be generic and usable for any data type and output type(s) as multiple outputs can be generated at the same time.
Full Script¶
The full script is shown below
Source Code
import os from pathlib import Path import urllib.request from random import shuffle import tarfile from autotransformers.dataset_loader import DatasetMeta from autotransformers import AutoTransformer, init_logging, ATDataset from autotransformers.types import IText from autotransformers.domains.text.types import TSingleClassification # # Custom ImdbDatasetLoader implementation # class ImdbDatasetLoader: # # The dataset loader must provide metadata (the model is coupled with some dataset version etc.) # a configuration (how the model is trained and what it expects as input and output) and the dataset itself. # The dataset must be provided via train_ds, test_ds and eval_ds. If the eval_ds is None, AT will automatically # split the train_ds into train and eval in order to avoid overfitting due to hyperparameter tuning. # def __init__(self, path) -> None: super().__init__() self.path = Path(path) self.train_ds = self._load("train") self.test_ds = self._load("test") self.eval_ds = None @property def meta(self): return DatasetMeta(name="IMDB", version="1.0.0", created_with="Manual") @property def config(self): # Models are always defined via inputs (text, document images) + combinations of expected outputs (classification, information extraction etc.) # The config can be used to set call names and to define ids in order to access the outputs later on again. # Finally, the dataset must be of the same structure to train the device AND predictions also return the same structure as shown below. return IText.Config(), ( TSingleClassification.Config(task_id="review", classes=["pos", "neg"]), ) def _load(self, name): if not self.path.exists(): self._download() samples_filenames = self._get_samples(name) def load_sample(idx): text_file, label = samples_filenames[idx] return (IText(text_file.read_text()), (TSingleClassification(label),)) return ATDataset(self.config, load_sample, length=len(samples_filenames)) def _download(self): print("Download IMDB dataset...") os.makedirs(self.path) tar_path = self.path / "aclImdb_v1.tar.gz" urllib.request.urlretrieve( # nosec B310 "http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz", tar_path, ) with tarfile.open(tar_path) as tar_file: tar_file.extractall(self.path) # nosec B202 os.remove(tar_path) def _get_samples(self, name): path = self.path / "aclImdb" / name samples = [(f, c) for c in ["pos", "neg"] for f in (path / c).iterdir()] shuffle(samples) return samples # # Train # def train(path_dataset, path_model, sys_config=None): dl = ImdbDatasetLoader(path=path_dataset) at = AutoTransformer(sys_config).init(dataset_loader=dl, path=path_model) test_metrics = at.train(dl) print(test_metrics) # Prints all metrics that are available for this model and domain. # For example: # Metric Value # ----------------------- -------- # review/test/accuracy 0.9468 # review/test/weighted_f1 0.946799 # review/test/loss 0.150823 # The "review" is set as we defined the task_id in the config above. # This way we can retrieve scores for each task individually. at.finish() del at return test_metrics # # Predict # def predict(path_model): at = AutoTransformer().load(path=path_model) # # Predict with IText as we defined this input in our specification above. # print("# Single sample prediction") input = IText("I really really love this movie") result = at(input) # As we defined the AT model to be a (IText, TSingleClassification), we know that the output of AT is the same, so -> (IText, TSingleClassification) # AutoTransformers returns a NamedTuple with input, output (can also be accessed via result.input, result.output and result[0], result[1]). # As we are the users of AT we can also set type hints in order to work with it later on. AT can't set specific type hints as predictions are dependent # on how the user trained AT, but the user must know this otherwise he/she can't train it. input: IText = result.input # == result[0] prediction: TSingleClassification = result.output # == result[1] print(type(input)) # Prints: <class 'autotransformers.types.IText'> print( type(prediction) ) # Prints: <class 'autotransformers.domains.text.types.TSingleClassification'> print("Value:", prediction.value) # Prints: Value: pos print("Confidence", prediction.confidence) # Prints: Confidence 0.9379566311836243 # Implicilty, we can also use a string that is internally converted to IText, sometimes nicer to read. print("\n# Sample prediction of string input") input = IText("I really really love this movie") output = at(input) print(output[1].value) # Prints: pos # We also allow batching of inputs in order to speed up predictions as we exploit the parallelism of GPUs better. # Then, the output is also a list with predictions for each sample. print("\n# Batched predictions and batched outputs") output = at( ["I really really love this movie", "I hate this movie, it was super boring"] ) assert all(isinstance(output[i].input, IText) for i in range(len(output))) assert all( isinstance(output[i].output, TSingleClassification) for i in range(len(output)) ) print(output[0].output.value) # Prints: pos print(output[1].output.value) # Prints: neg # Finally, we can clean up memory of the model. # Still we also need to delete the AutoTransformer object as it holds the model in memory on CPU + GPU. at.finish() del at # # Main # def main(): init_logging() path_dataset = ".data/text/imdb" path_model = ".models/MovieAT" # For this example, we train for only n steps to showcase how training works. # All configs can be found in `at main --domain=...` or you can use the # wizard to generate the correct setup. If nothing is specified, AT will # use hyperparameter optimization to find this. sys_config = [ ("engine/stop_condition/type", "MaxSteps"), ("engine/stop_condition/value", 300), ] # We train the model, in case its already trained we can skip this step # and directly predict and use our AT model. train(path_dataset, path_model, sys_config=sys_config) # Predict new samples predict(path_model) if __name__ == "__main__": main()
How to continue?¶
AutoTransformers provides even more features such as:
Checkpointing
Clearml or Wandb Logging
Early stopping
Active Learning
Document or Computer Vision tasks
…
We think that you can learn how to use the AutoTransformers library best with different real-world examples. We, therefore, provide many different tutorials in the next section and details in the API documentation section.