Getting Started - Wizard (Suggested)¶
In this tutorial, you will learn how you can use the AutoTransformers library and how to transform your custom data into an AutoTransformer model that can be used to automate different tasks. The AutoTransformers library supports many different input formats such as text, documents or text to ensure, that our customers can solve a huge range of problems with our library. Additionally, each AutoTransformer model can solve many different tasks in parallel as visualized in the image below:
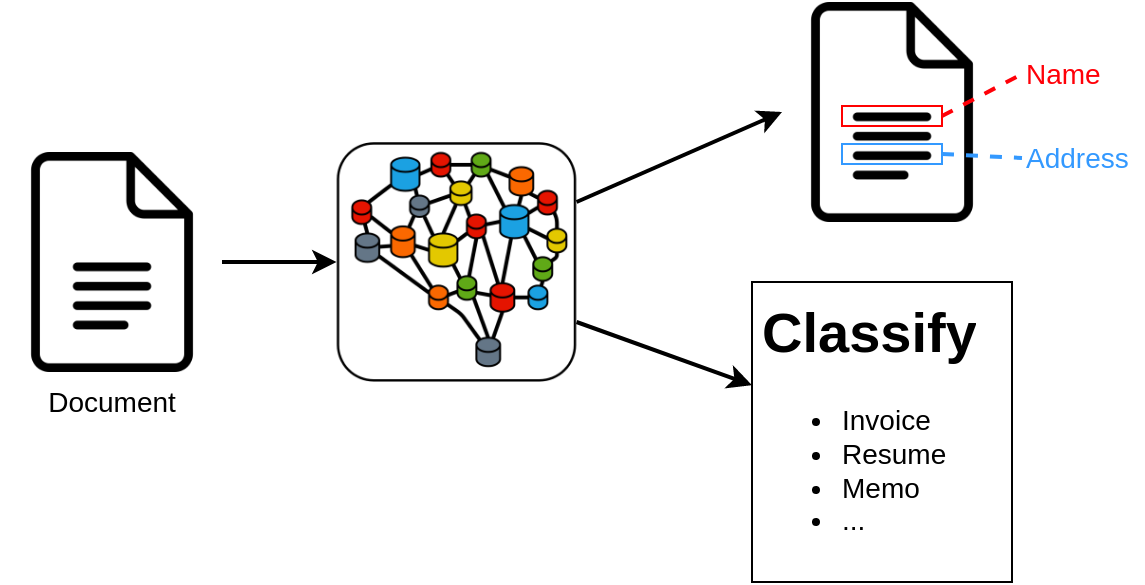
To list all input formats that are supported you can use help() or you can also use the AutoTransformers wizard to automatically generate your dataset template, train as well as predict script. The wizard will ask you a few questions and will then automatically generate the project for you. Also a README.md file is generated that helps you to get started with your project.
To start the wizard simply execute at wizard after you installed the AutoTransformers library. In the following example, we create a project that can be used to train an AutoTransformer for sentiment prediction. We also enable distributed training on multiple GPUs and we log performance metrics on WandDB.

An overview of the project and how different components in this project are connected is shown in the following overview:
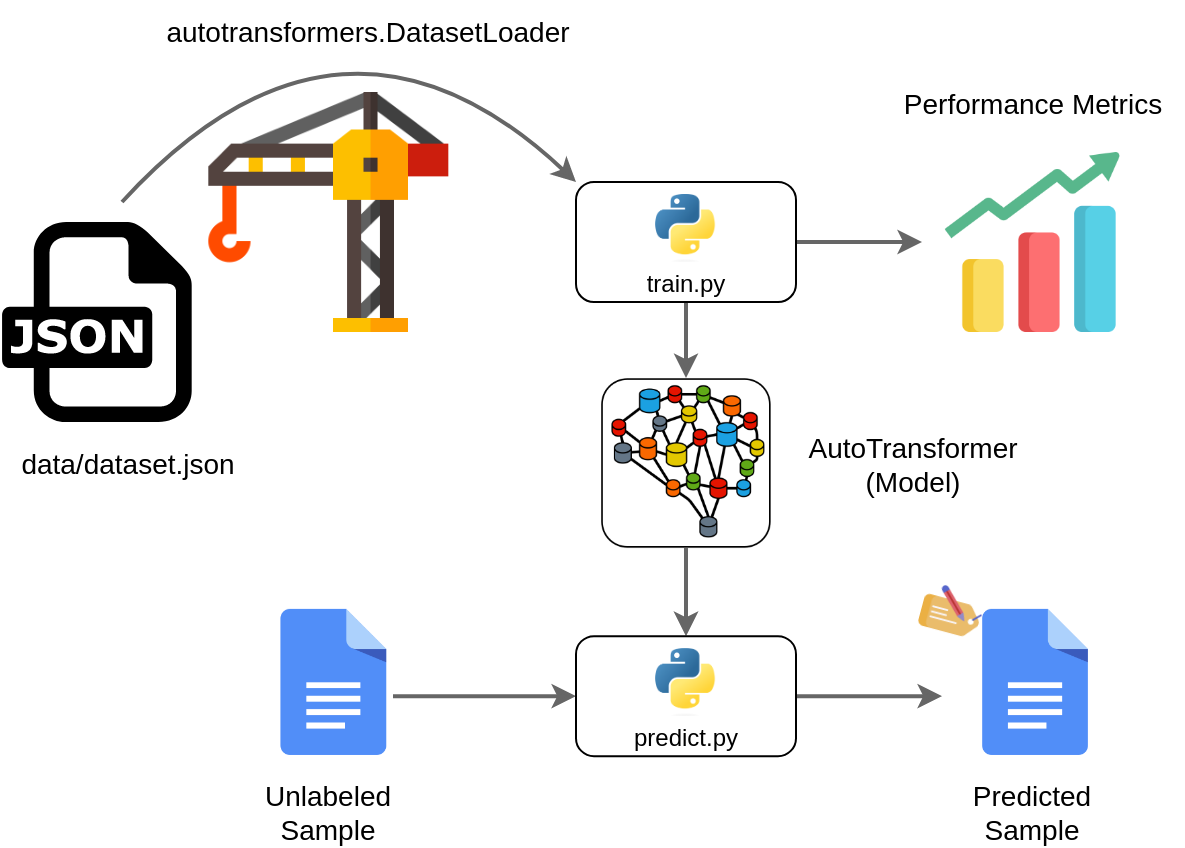
When you succesfully generated a new project, you must include the data. The AutoTransformers wizard generates the dataset/dataset.json file including the necessary configuration as well as one sample for each task that you selected. Simply open this file and check out how you can configure the data and you can also read the generated README.md file which includes information that is helpful. Note: Sometimes its required to reference other files (for example the document image). In this case, feel free to copy files directly into the dataset folder, or you can also create a subfolder such as docs. THen, simply reference the files in your dataset.json file via dataset/docs/DOC1.png.
When you successfully created the dataset you can train your model using the train.py script. Please check out the generated README.md on how to run your training script. When the model training is finished, you can use the predict.py script to generate predictions on new input values.
Note
We suggest that you update the version of the `dataset.json` file each time you change the dataset such that you can check later on how a model was trained.